在当今数据驱动型企业的技术架构中,Hadoop生态体系已成为处理海量数据的标准解决方案。本实战班聚焦Hadoop核心组件应用,通过真实商业场景下的数据处理案例,帮助学员建立完整的大数据处理能力框架。
| 技术模块 | 实训项目 | 技能目标 |
|---|---|---|
| HDFS分布式存储 | TB级日志文件存储优化 | 掌握数据分块策略与副本机制 |
| MapReduce编程 | 电商用户行为分析 | 实现复杂业务逻辑的MapReduce程序 |
| Hive数据仓库 | 金融交易数据统计分析 | 熟练使用HQL进行多维数据分析 |
| 教学维度 | 常规培训 | 本实战班 |
|---|---|---|
| 实验环境 | 单机伪分布式 | 多节点真实集群 |
| 项目规模 | Demo级案例 | TB级真实数据 |
| 故障处理 | 标准解决方案 | 企业级异常排查 |
课程采用阶梯式能力培养体系,从Hadoop基础组件到企业级调优层层递进。第三周重点讲解YARN资源调度机制,通过模拟双十量高峰场景,让学员掌握集群资源动态分配技巧。
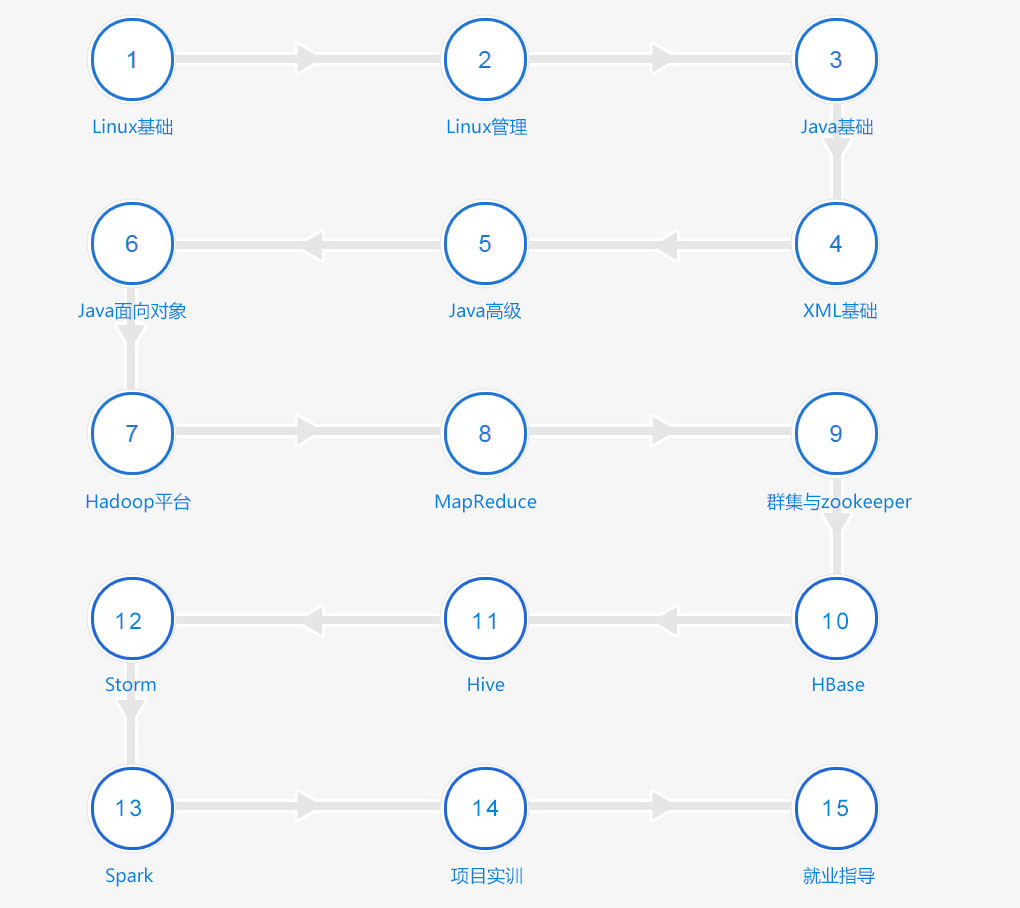
项目实战阶段采用敏捷开发模式,每个迭代周期包含需求分析、技术方案设计、代码实现和结果验收四个环节。结业项目要求学员独立完成从数据采集到可视化展示的完整数据处理流程。














